微信网页授权流程
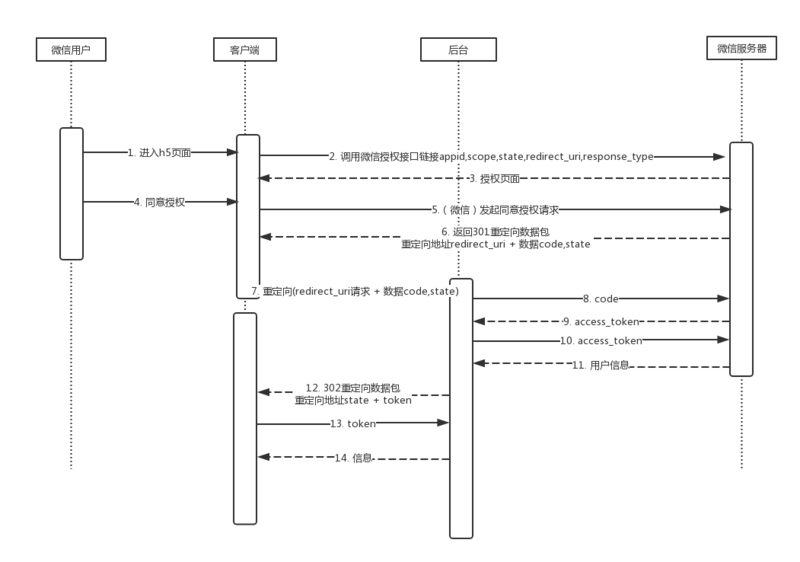
具体而言,可分为两步:
1、引导用户进入授权页面同意授权,获取code 【拉起授权页】
这里有两个参数比较注意的是:redirect_uri 授权成功后的跳转地址,授权作用域scope参数有两个值:snsapi_base和snsapi_userinfo。如果只需要获取openid则前者就够了,后者还可获取微信用户信息,前者的静默授权(不显示授权页面)功能也挺棒的。
若提示该链接无法访问,请检查参数是否填写错误,是否拥有scope参数对应的授权作用域权限。微信返回参数错误的原因一般有两种:一是在微信公众平台没有配置相应的参数;二是前端配置的接口参数与公众平台不一致。
具体参数说明
| 参数 | 是否必须 | 说明 |
|---|---|---|
| appid | 是 | 公众号的唯一标识 |
| redirect_uri | 是 | 授权后重定向的回调链接地址, 需要使用 urlencode 对链接进行处理,注意这个地址必须在公众号后台网页授权域名下 |
| response_type | 是 | 返回类型,填写code |
| scope | 是 | 应用授权作用域,snsapi_base (不弹出授权页面,直接跳转,只能获取用户openid),snsapi_userinfo (弹出授权页面,可通过openid拿到昵称、性别、所在地。并且, 即使在未关注的情况下,只要用户授权,也能获取其信息 ) |
| state | 否 | 重定向后会带上state参数,传递什么返回什么, 可以作为参数传递 |
| wechat_redirect | 是 | 无论直接打开还是做页面302重定向时候,必须带此参数 |
2、通过code换取网页授权access_token进而获取用户openid和其他用户信息【获取用户信息】
获取code后,请求以下链接获取access_token
https://api.weixin.qq.com/sns/oauth2/access_token?appid=APPID&secret=SECRET&code=CODE&grant_type=authorization_code
参数说明
| 参数 | 是否必须 | 说明 |
|---|---|---|
| appid | 是 | 公众号的唯一标识 |
| secret | 是 | 公众号的appsecret |
| code | 是 | 填写第一步获取的code参数 |
| grant_type | 是 | 填写为authorization_code |
正确时返回的JSON数据包如下:
1 | { |
拉取用户信息(需scope为 snsapi_userinfo)
如果网页授权作用域为snsapi_userinfo,则此时开发者可以通过access_token和openid拉取用户信息了。
http:GET(请使用https协议)
https://api.weixin.qq.com/sns/userinfo?access_token=ACCESS_TOKEN&openid=OPENID&lang=zh_CN
参数说明
| 参数 | 是否必须 | 说明 |
|---|---|---|
| access_token | 是 | 网页授权接口调用凭证,注意:此access_token与基础支持的access_token不同 |
| openid | 是 | 用户的唯一标识 |
| lang | 是 | 返回国家地区语言版本,zh_CN 简体,zh_TW 繁体,en 英语 |
正确时返回的JSON数据包如下:
1 | { |
注意:unionid 只有在开发者将公众号绑定到微信开放平台帐号后,才会出现该字段。
到此,微信网页授权也就结束了,更多请查看微信网页授权文档
针对RESTful规范修改
现代项目开发基本上都是采用完全的前后端分离开发模式,后端采用统一规范返回json或者jsonp等给前端,而前端不再是伪静态页面,而是存粹的静态HTML,用户请求基本上都是通过ajax此类异步请求完成后端数据接收的。而在官方推荐的流程中,redirect_url被定向到后端处理接口,处理完成后使用header等强制跳转处理后的页面的方式在此处就行不通了,因为它打破了前期统一制定好的代码规范。那么 redirect_url 定向到前端页面,让前端来接收Code是否可行呢? 答案是:可行。
超文本标记语言(HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言。HTML是一种基础技术,常与CSS、JavaScript一起被众多网站用于设计网页、网页应用程序以及移动应用程序的用户界面[3]。网页浏览器可以读取HTML文件,并将其渲染成可视化网页。HTML描述了一个网站的结构语义随着线索的呈现,使之成为一种标记语言而非编程语言。 —–wiki
我们知道html不是编程语言,是不能如php、java等编程语言那样获取用户请求参数的,但是GET请求例外,因为GET参数通过URL传递, 使用location.href或location.search是可以从URL中提取到GET参数的,代码如下:
1 | var getQueryVariable = (variable) => { |
回到正题,我们知道用户同意授权后,微信重定向时将code和state作为参数加到redirect_url链接上,也就是如下形式:
redirect_url?code=001EX7O42pPubS00IvO42KtjO42EX7O8&state
处理过程如下:
1、我们将redirect_url定向到前端静态处理的页面A
1 | A.html |
对应的后端接口:
1 |
|
2、页面A接收到code值以后,传递给后台
1 | A.html |
3、后台通过code执行授权步骤2。
1 | /** |
这样一来,整个交互过程便统一了, 效果如下:
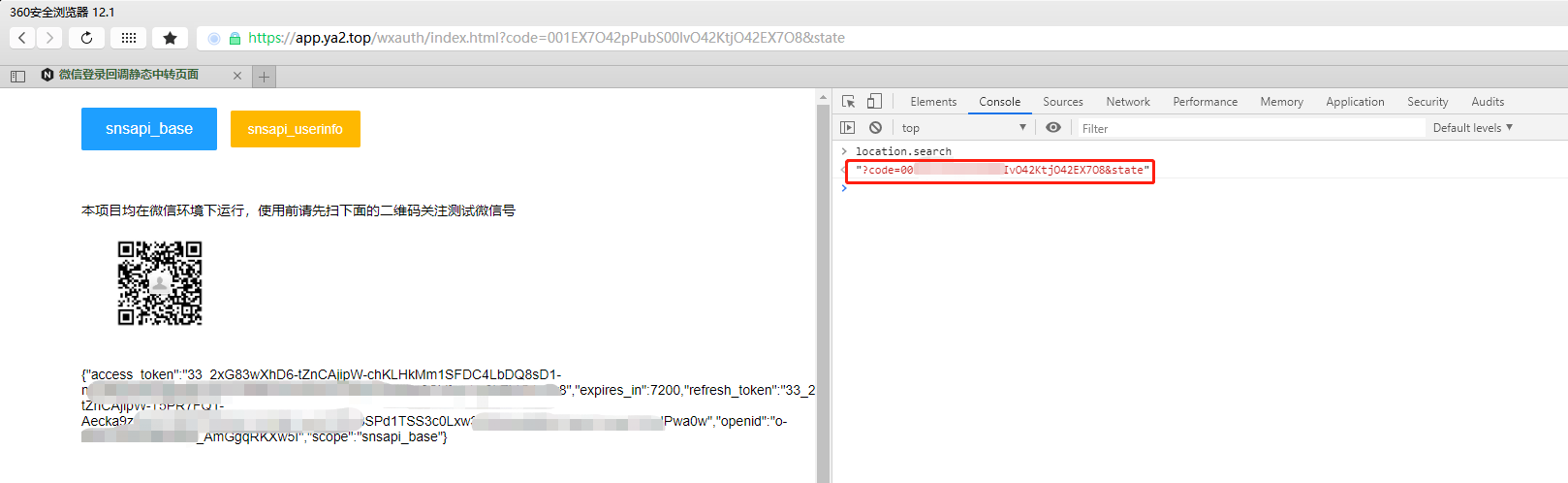
演示地址:https://app.ya2.top/wxauth/ (建议在微信环境打开)
源码地址:https://github.com/gouyuwang/wxauth/