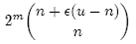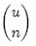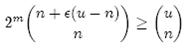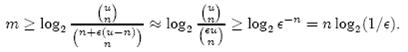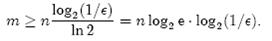前言
作者发现很多PC页面都没有做移动端转发的功能,有时候想在移动端阅读都要先在电脑上登录微信或者QQ转发到手机上面,一次两次还好,多了就觉得很不方便了,尤其是开发调试的时候。于是作者想到了开发一款浏览器插件简化一下上面的操作。
先上一下折腾出的成果 Github传送门:
正题
浏览器插件是一种小型的用于定制浏览器体验的程序。通过插件,我们可以定制js爬虫、屏蔽网页广告,网页实时查词,修改http请求头,等等,能做的东西很多。只要你会HTML,JavaScript,CSS就可以动手开发浏览器插件了。
1、创建manifest.json。任何插件都必须要有这个文件,用来描述插件的元数据,插件的配置信息。
1 | { |
2、编写业务
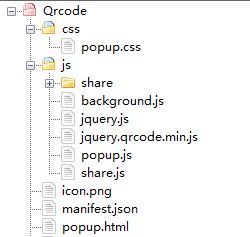
里面内容比较简单,生成二维码和分享均用的三方插件。值得注意的是,html里面不能和js混写,这里涉及到一个权限问题。

3、运行调试
- 进入浏览器扩展管理
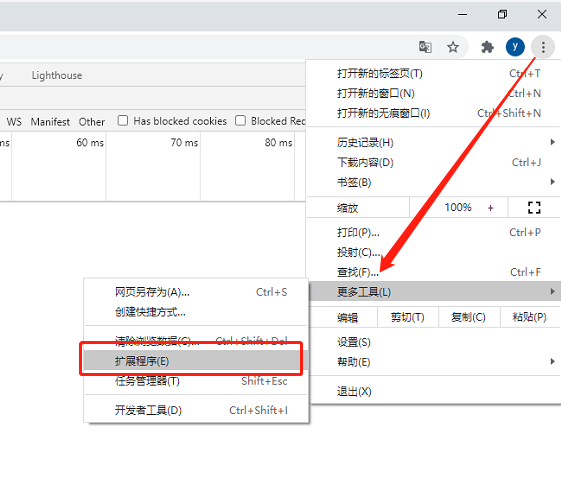
- 开发者模式打开,然后点击 “加载已解压的扩展程序” 将创建的插件目录导入进去,如果你只有crx文件,直接右键以压缩文件方式解压就可以看到全部代码。

- 成功后可以看到下面的画面
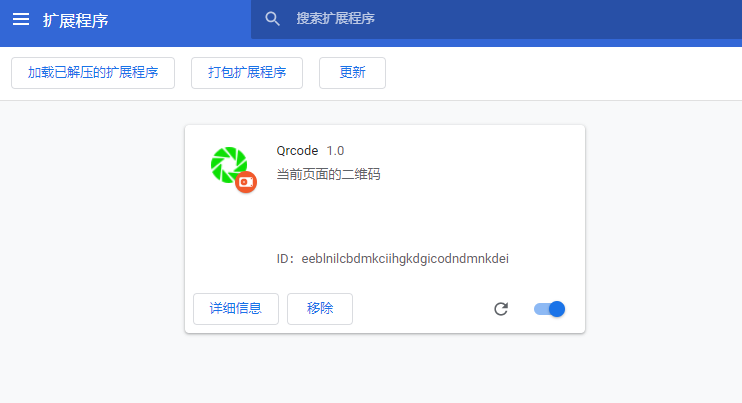
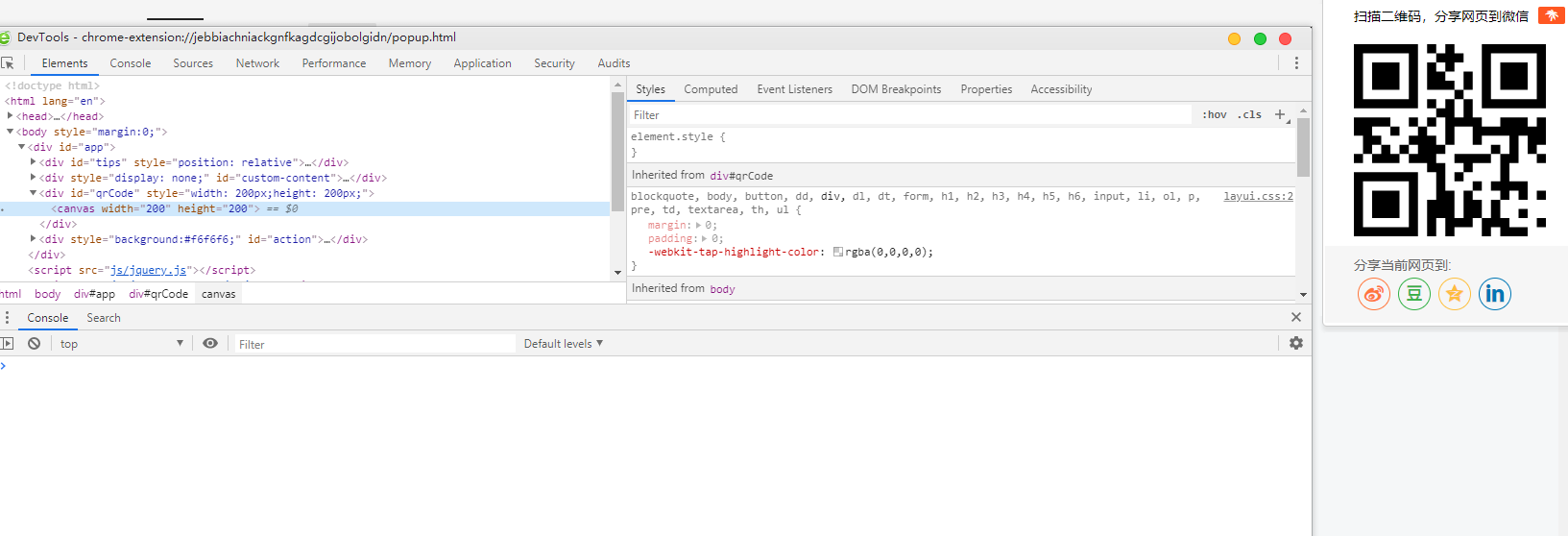
调试的跟普通网页调试差不多,右键点击弹出的扩展,点“审查元素”即可打开插件的开发工具,如图
4、打包发布
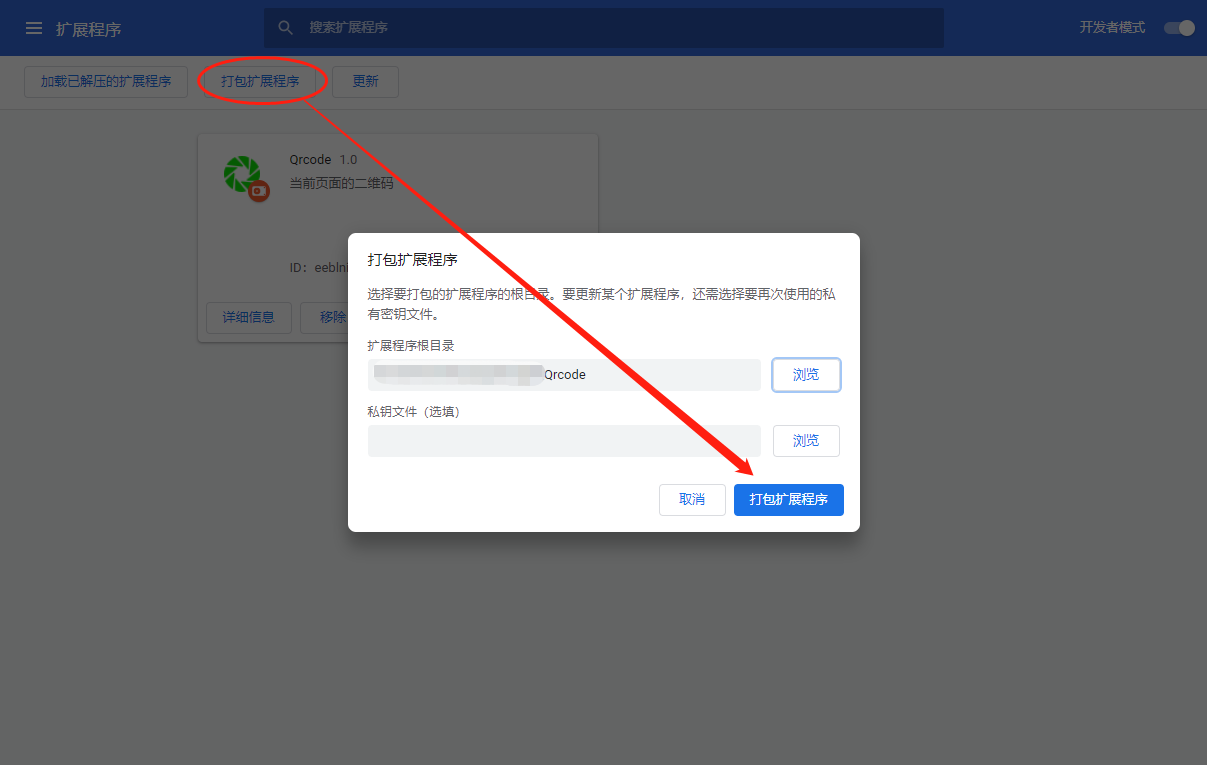
打包后会生成.crx文件,将生成的.crx项目文件直接拖入浏览器,也可以在扩展程序里面添加,Google对这个审核还是比较严格的,禁止未上架的插件拖曳使用,但是可以以开发者模式安装。 亲测360浏览器是可以直接拖曳的使用的。
总结
浏览器插件开发,具有很高的实用性,值得我们去学习和了解。本文是作者记录第一次学习制作插件开发的过程,内容只是作者所用到的部分,未能面面俱到,敬请谅解。
欢迎一起讨论与留言。