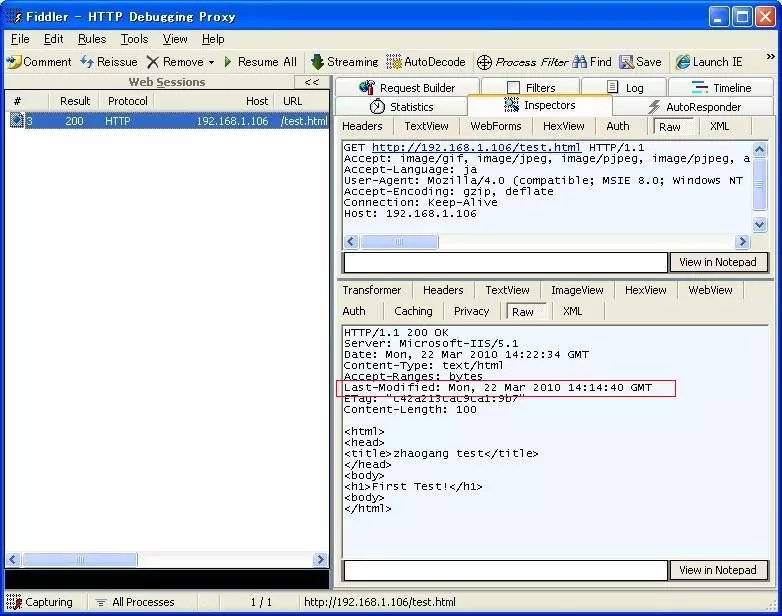
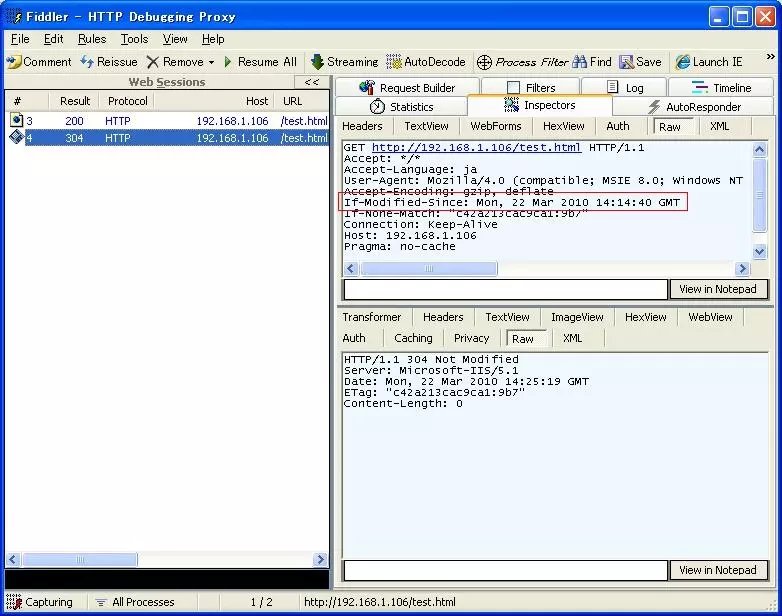
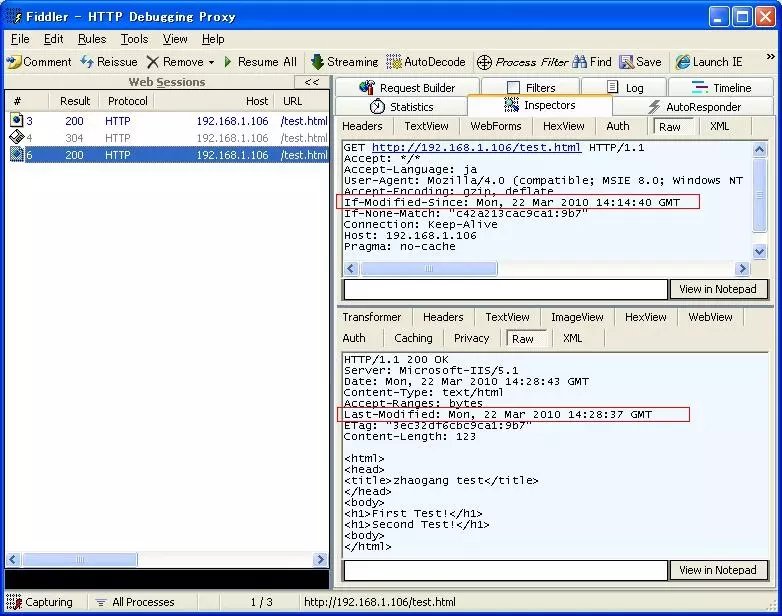
ACSII规定:一个字符由一个字节存储。范围:前32位(0x00 — 0x20)为控制码。第32位至127位(0x20 — 0x7f)为空格、标点符号、数字、字母。127位以后不用。
扩展字符集
原因: 由于其它国家的字符太多,ASCII标准已经不够用,所以他们启用了127位以后的全部空位。
GB2312
原因:由于其它国家制定的扩展字符集并不适用于中文,所以中国人重新制定了符合本国国情的编码方式:GB2312(GB2312是对ASCII码的中文扩展)。规定:小于127的字符意义同ASCII标准一样,但两个大于127的字符连在一起时,就表示一个汉字。范围:前一个字节(高字节)使用范围为:0xa1 — 0xf7后一个字节(低字节)使用范围为:0xa1 — oxfe
GBK
原因:后来由于汉字实在太多,GB2312已经不够使用了,于是又制定了新的编码:GBK,取消了GB2312中对汉字低字节的限制。规定: 小于127的字符意义同ASCII标准一样,如果遇到大于127位的字节则无论其后的一个字节是否是大于127都将这个两个字节视为一个汉字(GB2312要求两个字节都要大于127,但GBK取消了对低字节的要求)。范围:前一个字节(高字节)使用范围为:0x81 — 0xfe后一个字节(低字节)使用范围为:0x40 — 0xfe
GB18030
原因: 由于GBK并没有包含少数民族的文字字符,所以又再次对GBK进行扩展以包含少数名族字符,由此又制定了新的编码GB18030,从此该编码方式可以完全表示中华民族的所有字符了。
小结:人们为了统一称呼这些【汉字】编码方式,于是把它们都叫做DBCS(Double Byte Charecter Set,双字节字符集),它们最大的特点就是两个字节长的汉字字符和一个字节长的英文字符并存在一套编码系统里。因此在处理这些编码时要时刻注意每一个字节的值是否是大于127,如果小于则取按照ASCII标准取值,如过大于则表示一个汉字开始了,这时就要和它和后面一个字节一起组合起来识别为一个汉字字符。
Unicode
原因: 由于每个国家都制定了自己的一套编码体系,造成各个国家之间的字符编码互不兼容,于是ISO组织统一制定了能包含全球所有文化、字符、符号的编码标准:Universal Multiple-Octet Coded Character Set”,简称 UCS, 俗称 “UNICODE”。规定: Unicode规定所有字符都统一使用两个字节编码,即使用16位来统一表示所有字符,对于ASCII标准的字符保持其值不变,但字节长度由一个字节变成两个字节,所以英文字符的Unicode编码的高字节永远都为0,因此也造成了存储空间的浪费。
UTF-8
定义: UTF即UCS Transfer Format(Unicode传输格式),utf-8是在网络上传输Unicode字符的一项标准,它是Unicode的主要实现方式之一。它每次传输8位数据,但它并不是直接对应Unicode的字节的值,而是为了传输的可靠性制定了一套从Unicode到utf-8的转换规则。转换规则:
| Unicode | UTF-8 |
|---|---|
| 0000 - 007F | 0xxxxxxx |
| 0080 - 07FF | 110xxxxx 10xxxxxx |
| 0800 - FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
举例: ‘汉’字的Unicode编码是:6C49,通过上表可以得出,它在0x0800到0xffff之间,所以它需要使用3个字节来传输,将6C49转位二进制: 0110 1100 0100 1001,按照utf-8的格式转换,第一个字节为:[1110]0110,第二个字节为:[10]110001,第三个字节为:[10]001001,所以将‘汉’字的unicode转换为utf-8之后的二进制是:11100110 10110001 10001001 ,即16进制E6 B1 89
单字节: 由一个字节构成一个字符的编码。如ASCII
多字节: 由一个或多个字节构成一个字符的编码。如GB2312、GBK宽字节: 始终由两个字节构成一个字符的编码。如Unicode