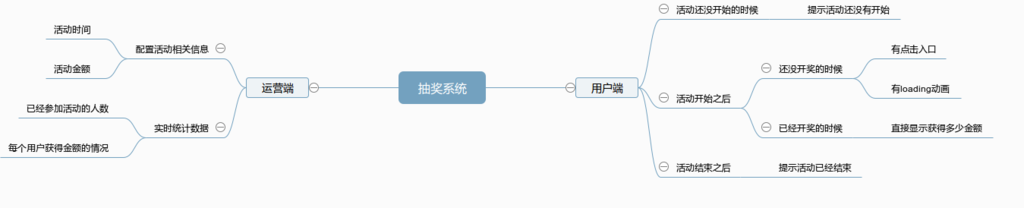
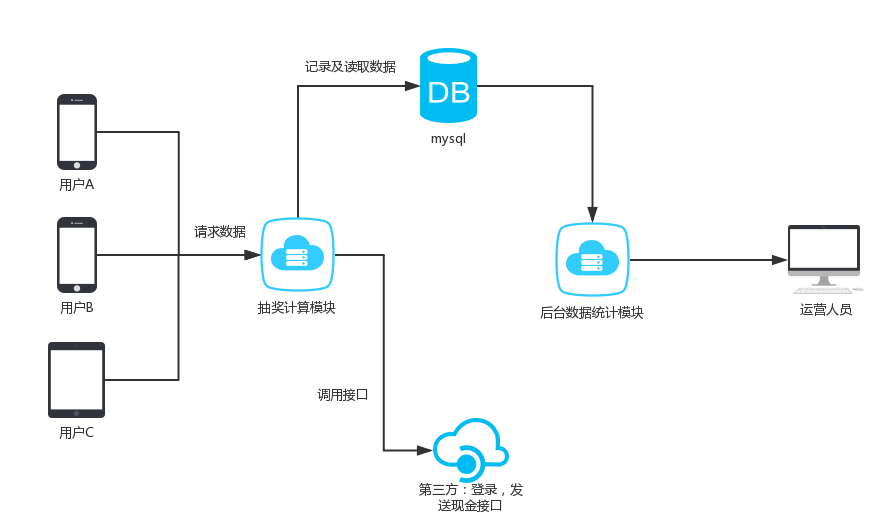
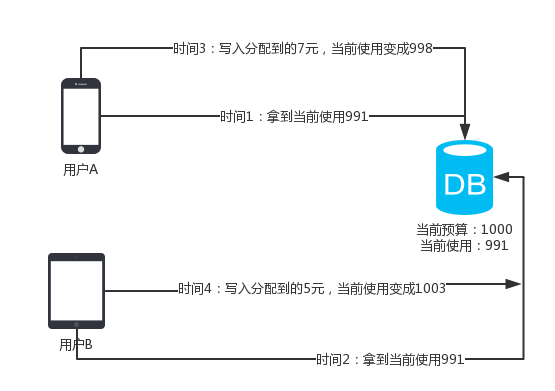
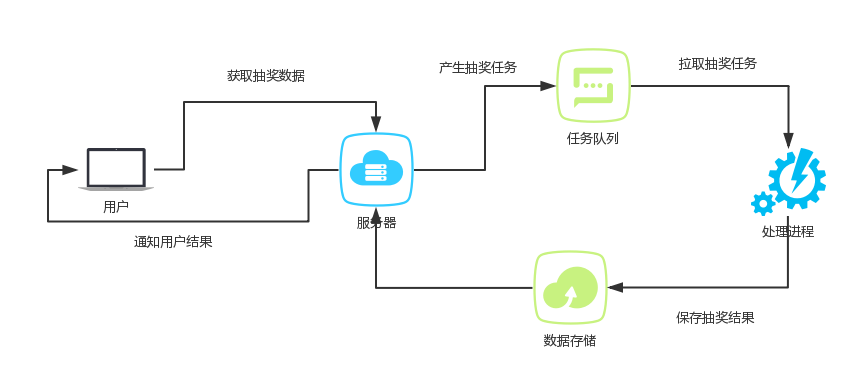
安排命令和程序定期运行或在指定时间内运行。从计划表中添加和删除任务,按需要启动和停止任务,显示和更改计划任务。
语法
1 | schtasks /create /tn TaskName /tr TaskRun /sc schedule [/momodifier] [/dday] [/mmonth[,month...] [/iIdleTime] [/stStartTime] [/sdStartDate] [/edEndDate] [/scomputer[/u[domain\]user/ppassword]][/ru{[Domain\]User|"System"} [/rpPassword]] /? |
参数
/tn TaskName 指定任务的名称。
/tr TaskRun 指定任务运行的程序或命令。键入可执行文件、脚本文件或批处理文件的完全合格的路径和文件名。如果忽略该路径,SchTasks.exe 将假定文件在Systemroot\System32 目录下。
/sc schedule 指定计划类型。有效值为 MINUTE、HOURLY、DAILY、WEEKLY、MONTHLY、ONCE、ONSTART、ONLOGON、ONIDLE。
1 | 有效值说明 |
/mo modifier 指定任务在其计划类型内的运行频率。这个参数对于 MONTHLY 计划是必需的。对于 MINUTE、HOURLY、DAILY 或 WEEKLY 计划,这个参数有效,但也可选。默认值为 1。
1 | 参数说明 |
/d dirlist 指定周或月的一天。只与 WEEKLY 或 MONTHLY 计划共同使用时有效。
1 | 计划类型 |
/m month[,month…] 指定一年中的一个月。有效值是 JAN ~ DEC 和 * (每个月)。/m参数只对于 MONTHLY 计划有效。在使用 LASTDAY 修饰符时,这个参数是必需的。否则,它是可选的,默认值是 * (每个月)。
/i InitialPageFileSize 指定任务启动之前计算机空闲多少分钟。键入一个1 ~ 999之间的整数。这个参数只对于 ONIDLE 计划有效,而且是必需的。
/st StartTime 以HH:MM:SS24 小时格式指定时间。默认值是命令完成时的当前本地时间。/st参数只对于 MINUTE、HOURLY、DAILY、WEEKLY、MONTHLY 和 ONCE 计划有效。它只对于 ONCE 计划是必需的。
/sd StartDate 以MM/DD/YYYY格式指定任务启动的日期。默认值是当前日期。/sd参数对于所有的计划有效,但只对于 ONCE 计划是必需的。
/ed EndDate 指定任务计划运行的最后日期。此参数是可选的。它对于 ONCE、ONSTART、ONLOGON 或 ONIDLE 计划无效。默认情况下,计划没有结束日期。
/s Computer 指定远程计算机的名称或 IP 地址(带有或者没有反斜杠)。默认值是本地计算机。
/u [domain]user 使用特定用户帐户的权限运行命令。默认情况下,使用已登录到运行 SchTasks 的计算机上的用户的权限运行命令。
/p password 指定在/u参数中指定的用户帐户的密码。如果使用/u参数,则需要该参数。
/ru {[Domain]User|”System”} 使用指定用户帐户的权限运行任务。默认情况下,使用用户登录到运行 SchTasks 的计算机上的权限运行任务。
1 | 值说明 |
/p Password 指定用户帐户的密码,该用户帐户在/u参数中指定。如果在指定用户帐户的时候忽略了这个参数,SchTasks.exe 会提示您输入密码而且不显示键入的文本。使用 NT Authority\System 帐户权限运行的任务不需要密码,SchTasks.exe 也不会提示索要密码。
/? 在命令提示符显示帮助。
范例
计划任务每 20 分钟运行一次
下面的命令计划安全脚本 Sec.vbs 每 20 分钟运行一次。由于命令没有包含起始日期或时间,任务在命令完成 20 分钟后启动,此后每当系统运行它就每 20 分钟运行一次。请注意,安全脚本源文件位于远程计算机上,但任务在本地计算机上计划并执行。
1 | schtasks /create /sc minute /mo 20 /tn "Security scrīpt" /tr \\central\data\scrīpts\sec.vbs |
计划命令在每小时过五分的时候运行
下面的命令将计划 MyApp 程序从午夜过后五分钟起每小时运行一次。因为忽略了/mo参数,命令使用了小时计划的默认值,即每 (1) 小时。如果该命令在 12:05 A.M 之后生成,程序将在第二天才会运行。
schtasks /create /sc hourly /st 00:05:00 /tn “My App” /tr c:\apps\myapp.exe
计划命令每五小时运行一次
下面的命令计划 MyApp 程序从 2001 年 3 月的第一天起每五小时运行一次。它使用/mo参数来指定间隔时间,使用/sd参数来指定起始日期。由于命令没有指定起始时间,当前时间被用作起始时间。
1 | schtasks /create /sc hourly /mo 5 /sd 03/01/2001 /tn "My App" /tr c:\apps\myapp.exe |
计划任务每天运行一次
下面的范例计划 MyApp 程序在每天的 8:00 A.M. 运行一次,直到 2001 年 12 月 31 日结束。由于它忽略了/mo参数,所以使用默认间隔 1 来每天运行命令。
1 | schtasks /create /tn "My App" /tr c:\apps\myapp.exe /sc daily /st 08:00:00 /ed 12/31/2001 |
计划任务每六周运行一次
下面的命令计划 MyApp 程序在远程计算机上每六周运行一次。该命令使用/mo参数来指定间隔。它也使用/s参数来指定远程计算机,使用/ru参数来计划任务以用户的 Administrator 帐户权限运行。因为忽略了/rp参数,SchTasks.exe 会提示用户输入 Administrator 帐户密码。
另外,因为命令是远程运行的,所以命令中所有的路径,包括到 MyApp.exe 的路径,都是指向远程计算机上的路径。
1 | schtasks /create /tn "My App" /tr c:\apps\myapp.exe /sc weekly /mo 6 /s Server16 /ru Admin01 |
如何关闭dos窗口提示
1 | // 使用vbs 在后台静默执行 |