永久开启端口
firewall-cmd --add-port=3128/tcp --permanent
查询端口是否开启
firewall-cmd --query-port=3128/tcp
启动firewall
systemctl start firewalld.service
停止firewall
systemctl stop firewalld.service
1、只是下载远程的库的内容,不做任何的合并
git fetch --all
2、把HEAD指向刚刚下载的最新的版本
git reset --hard origin/master
第一种情况:改动没有被提交(commit)。
这种情况下,使用svn
revert就能取消之前的修改。
svn revert用法如下:
# svn revert [-R] something
其中something可以是(目录或文件的)相对路径也可以是绝对路径。
当something为单个文件时,直接svn revert something就行了;当something为目录时,需要加上参数-R(Recursive,递归),否则只会将something这个目录的改动。
在这种情况下也可以使用svn update命令来取消对之前的修改,但不建议使用。因为svn update会去连接仓库服务器,耗费时间。
注意:svn revert本身有固有的危险,因为它的目的是放弃未提交的修改。一旦你选择了恢复,Subversion没有方法找回未提交的修改。
第二种情况:改动已经被提交(commit)。
这种情况下,用svn merge命令来进行回滚。
回滚的操作过程如下:
1、保证我们拿到的是最新代码:
svn update
假设最新版本号是28。
2、然后找出要回滚的确切版本号:
svn log [something]
假设根据svn log日志查出要回滚的版本号是25,此处的something可以是文件、目录或整个项目
如果想要更详细的了解情况,可以使用svn diff -r 28:25 [something]
3、回滚到版本号25:
svn merge -r 28:25 something
为了保险起见,再次确认回滚的结果:
svn diff [something]
发现正确无误,提交。
4、提交回滚:
svn commit -m "Revert revision from r28 to r25,because of ..."
提交后版本变成了29。
将以上操作总结为三条如下:
svn update,svn log,找到最新版本(latest revision)
找到自己想要回滚的版本号(rollbak revision)
用svn merge来回滚: svn merge -r : something
核心命令:path/mysqldump –opt -u数据库账号 -p数据库密码 > 备份文件名
备份脚本 ( mysql_back.sh):
1 |
|
定时执行脚本:
例如; 每天晚上0点执行
在终端下执行 crontab -e(需要root权限),进入vi编辑窗口,添加一行:
0 0 * * * /root/mysql_dump/mysql_back.sh
备份脚本(mysql_back.bat) :
1 | @echo off |
定时执行脚本:
1 | schtasks /create /tn "任务名字" /tr d:/backup/mysql_back.bat /sc daily /st 00:00 /ed 31/12/2017 |
最近想做个小程序,需要用到授权认证流程。以前项目都是用的 OAuth2 认证,但是Sanic 使用OAuth2 不太方便,就想试一下 JWT 的认证方式。这一篇主要内容是 JWT 的认证原理,以及python 使用 jwt 认识的实践。
几种常用的认证机制
HTTP Basic Auth 在HTTP中,基本认证是一种用来允许Web浏览器或其他客户端程序在请求时提供用户名和口令形式的身份凭证的一种登录验证方式,通常用户名和明码会通过HTTP头传递。
在发送之前是以用户名追加一个冒号然后串接上口令,并将得出的结果字符串再用Base64算法编码。例如,提供的用户名是Aladdin、口令是open sesame,则拼接后的结果就是Aladdin:open sesame,然后再将其用Base64编码,得到QWxhZGRpbjpvcGVuIHNlc2FtZQ==。最终将Base64编码的字符串发送出去,由接收者解码得到一个由冒号分隔的用户名和口令的字符串。
优点
基本认证的一个优点是基本上所有流行的网页浏览器都支持基本认证。
缺点
由于用户名和密码都是Base64编码的,而Base64编码是可逆的,所以用户名和密码可以认为是明文。所以只有在客户端和服务器主机之间的连接是安全可信的前提下才可以使用。
接下来我们看一个更加安全也适用范围更大的认证方式 OAuth。
OAuth 是一个关于授权(authorization)的开放网络标准。允许用户提供一个令牌,而不是用户名和密码来访问他们存放在特定服务提供者的数据。现在的版本是2.0版。
严格来说,OAuth2不是一个标准协议,而是一个安全的授权框架。它详细描述了系统中不同角色、用户、服务前端应用(比如API),以及客户端(比如网站或移动App)之间怎么实现相互认证。
名词定义
Third-party application: 第三方应用程序,又称”客户端”(client)
HTTP service:HTTP服务提供商
Resource Owner:资源所有者,通常称”用户”(user)。
User Agent:用户代理,比如浏览器。
Authorization server:认证服务器,即服务提供商专门用来处理认证的服务器。
Resource server:资源服务器,即服务提供商存放用户生成的资源的服务器。它与认证服务器,可以是同一台服务器,也可以是不同的服务器。
OAuth 2.0 运行流程如图:
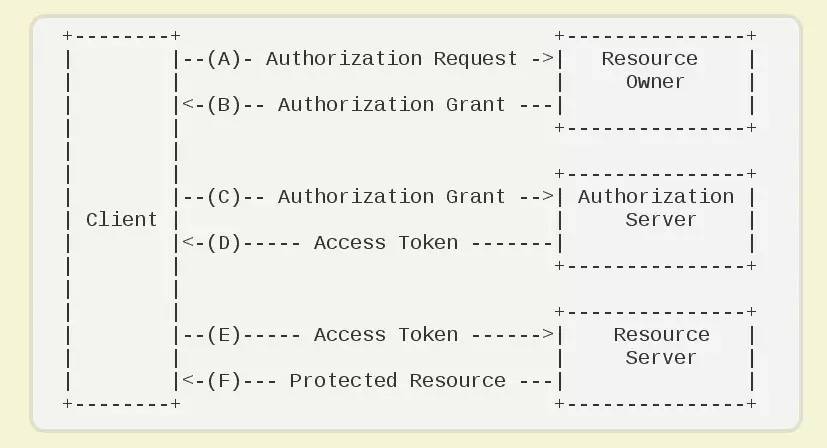
(A)用户打开客户端以后,客户端要求用户给予授权。
(B)用户同意给予客户端授权。
(C)客户端使用上一步获得的授权,向认证服务器申请令牌。
(D)认证服务器对客户端进行认证以后,确认无误,同意发放令牌。
(E)客户端使用令牌,向资源服务器申请获取资源。
(F)资源服务器确认令牌无误,同意向客户端开放资源。
优点
1 | 快速开发 |
缺点:
1 | OAuth2是一个安全框架,描述了在各种不同场景下,多个应用之间的授权问题。有海量的资料需要学习,要完全理解需要花费大量时间。 |
OAuth2不是一个严格的标准协议,因此在实施过程中更容易出错。
了解了以上两种方式后,现在终于到了本篇的重点,JWT 认证。
Json web token (JWT), 根据官网的定义,是为了在网络应用环境间传递声明而执行的一种基于JSON的开放标准((RFC 7519).该token被设计为紧凑且安全的,特别适用于分布式站点的单点登录(SSO)场景。JWT的声明一般被用来在身份提供者和服务提供者间传递被认证的用户身份信息,以便于从资源服务器获取资源,也可以增加一些额外的其它业务逻辑所必须的声明信息,该token也可直接被用于认证,也可被加密。
体积小,因而传输速度快
传输方式多样,可以通过URL/POST参数/HTTP头部等方式传输
严格的结构化。它自身(在 payload 中)就包含了所有与用户相关的验证消息,如用户可访问路由、访问有效期等信息,服务器无需再去连接数据库验证信息的有效性,并且 payload 支持为你的应用而定制化。
支持跨域验证,可以应用于单点登录。
JWT是Auth0提出的通过对JSON进行加密签名来实现授权验证的方案,编码之后的JWT看起来是这样的一串字符:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9.TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ
由 . 分为三段,通过解码可以得到:
1 | { |
jwt的头部包含两部分信息:
声明类型,这里是jwt
声明加密的算法 通常直接使用 HMAC SHA256
然后将头部进行base64加密(该加密是可以对称解密的),构成了第一部分。
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ92. 载荷(payload)
载荷就是存放有效信息的地方。这些有效信息包含三个部分:
公共的声明可以添加任何的信息,一般添加用户的相关信息或其他业务需要的必要信息.但不建议添加敏感信息,因为该部分在客户端可解密。
私有声明是提供者和消费者所共同定义的声明,一般不建议存放敏感信息,因为base64是对称解密的,意味着该部分信息可以归类为明文信息。
下面是一个例子:
1 | // 包括需要传递的用户信息; |
iss: 该JWT的签发者,是否使用是可选的;
sub: 该JWT所面向的用户,是否使用是可选的;
aud: 接收该JWT的一方,是否使用是可选的;
exp(expires): 什么时候过期,这里是一个Unix时间戳,是否使用是可选的;
iat(issued at): 在什么时候签发的(UNIX时间),是否使用是可选的;
其他还有:
nbf (Not Before):如果当前时间在nbf里的时间之前,则Token不被接受;一般都会留一些余地,比如几分钟;,是否使用是可选的;
jti: jwt的唯一身份标识,主要用来作为一次性token,从而回避重放攻击。
将上面的JSON对象进行base64编码可以得到下面的字符串。这个字符串我们将它称作JWT的Payload(载荷)。
eyJpc3MiOiJPbmxpbmUgSldUIEJ1aWxkZXIiLCJpYXQiOjE0MTY3OTc0MTksImV4cCI6
MTQ0ODMzMzQxOSwiYXVkIjoid3d3Lmd1c2liaS5jb20iLCJzdWIiOiIwMTIzNDU2Nzg5Iiwibmlja25hbWUiOiJnb29kc3BlZWQiLCJ1c2VybmFtZSI6Imdvb2RzcGVlZCIsInNjb3BlcyI6WyJhZG1pbiIsInVzZXIiXX0
信息会暴露:由于这里用的是可逆的base64 编码,所以第二部分的数据实际上是明文的。我们应该避免在这里存放不能公开的隐私信息。
HMACSHA256(
base64UrlEncode(header) + “.” +
base64UrlEncode(payload),
SECREATE_KEY
)
jwt的第三部分是一个签证信息,这个签证信息由三部分组成:
header (base64后的)
payload (base64后的)
secret
将上面的两个编码后的字符串都用句号.连接在一起(头部在前),就形成了:
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJpc3MiOiJKb2huIFd1IEpXVCIsImlhdCI6MTQ0MTU5MzUwMiwiZXhwIjoxNDQxNTk0NzIyLCJhdWQiOiJ3d3cuZXhhbXBsZS5jb20iLCJzdWIiOiJqcm9ja2V0QGV4YW1wbGUuY29tIiwiZnJvbV91c2VyIjoiQiIsInRhcmdldF91c2VyIjoiQSJ9
最后,我们将上面拼接完的字符串用HS256算法进行加密。在加密的时候,我们还需要提供一个密钥(secret)。如果我们用 secret作为密钥的话,那么就可以得到我们加密后的内容:
pq5IDv-yaktw6XEa5GEv07SzS9ehe6AcVSdTj0Ini4o
将这三部分用.连接成一个完整的字符串,构成了最终的jwt:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJPbmxpbmUgSldUIEJ1aWxkZXIiLCJpYXQiOjE0MTY3OTc0MTksImV4cCI6MTQ0ODMzMzQxOSwiYXVkIjoid3d3Lmd1c2liaS5jb20iLCJzdWIiOiIwMTIzNDU2Nzg5Iiwibmlja25hbWUiOiJnb29kc3BlZWQiLCJ1c2VybmFtZSI6Imdvb2RzcGVlZCIsInNjb3BlcyI6WyJhZG1pbiIsInVzZXIiXX0.pq5IDv-yaktw6XEa5GEv07SzS9ehe6AcVSdTj0Ini4o
签名的目的:签名实际上是对头部以及载荷内容进行签名。所以,如果有人对头部以及载荷的内容解码之后进行修改,再进行编码的话,那么新的头部和载荷的签名和之前的签名就将是不一样的。而且,如果不知道服务器加密的时候用的密钥的话,得出来的签名也一定会是不一样的。
这样就能保证token不会被篡改。
token 生成好之后,接下来就可以用token来和服务器进行通讯了。
下图是client 使用 JWT 与server 交互过程:
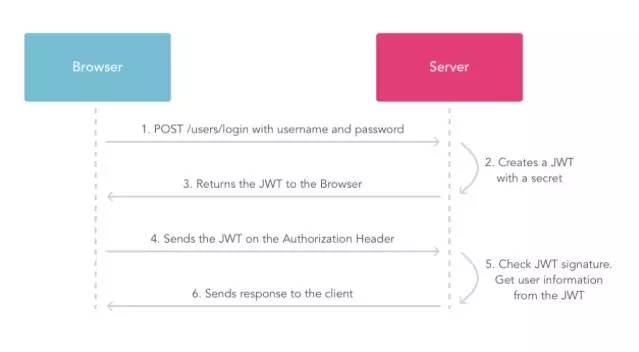
这里在第三步我们得到 JWT 之后,需要将JWT存放在 client,之后的每次需要认证的请求都要把JWT发送过来。(请求时可以放到 header 的 Authorization )
JWT 使用场景
JWT的主要优势在于使用无状态、可扩展的方式处理应用中的用户会话。服务端可以通过内嵌的声明信息,很容易地获取用户的会话信息,而不需要去访问用户或会话的数据库。在一个分布式的面向服务的框架中,这一点非常有用。
但是,如果系统中需要使用黑名单实现长期有效的token刷新机制,这种无状态的优势就不明显了。
优点
1 | 快速开发 |
缺点
1 | Token有长度限制 |
解释如下: =+是不存在的;
+new Date()是一个东西;
+ 相当于.valueOf();
下面4个结果一样,都返回当前时间的毫秒数
1 |
|
获取当前时间
1 | var myDate = new Date(); |
顺便说下valueOf的另一个用法:
valueOf() 方法可返回 Boolean 对象的原始值。
如果调用该方法的对象不是 Boolean,则抛出异常 TypeError。
1 | var boo = new Boolean(false); |
除了正常运行模式,ECMAscript 5添加了第二种运行模式:“严格模式”(strict mode)。顾名思义,这种模式使得Javascript在更严格的条件下运行。
设立”严格模式”的目的,主要有以下几个:
消除Javascript语法的一些不合理、不严谨之处,减少一些怪异行为;
消除代码运行的一些不安全之处,保证代码运行的安全;
提高编译器效率,增加运行速度;
为未来新版本的Javascript做好铺垫。
“严格模式”体现了Javascript更合理、更安全、更严谨的发展方向,包括IE 10在内的主流浏览器,都已经支持它,许多大项目已经开始全面拥抱它。
另一方面,同样的代码,在”严格模式”中,可能会有不一样的运行结果;一些在”正常模式”下可以运行的语句,在”严格模式”下将不能运行。掌握这些内容,有助于更细致深入地理解Javascript,让你变成一个更好的程序员。
本文将对”严格模式”做详细介绍。
进入”严格模式”的标志,是下面这行语句:
1 | ; |
老版本的浏览器会把它当作一行普通字符串,加以忽略。
“严格模式”有两种调用方法,适用于不同的场合。
将”use strict”放在脚本文件的第一行,则整个脚本都将以”严格模式”运行。如果这行语句不在第一行,则无效,整个脚本以”正常模式”运行。如果不同模式的代码文件合并成一个文件,这一点需要特别注意。
(严格地说,只要前面不是产生实际运行结果的语句,”use strict”可以不在第一行,比如直接跟在一个空的分号后面。)
1 | ; |
1 | console.log("这是正常模式。");kly, it's almost 2 years ago now. I can admit it now - I run it on my school's network that has about 50 computers. |
上面的代码表示,一个网页中依次有两段Javascript代码。前一个script标签是严格模式,后一个不是。
将”use strict”放在函数体的第一行,则整个函数以”严格模式”运行。
1 | function strict(){ |
因为第一种调用方法不利于文件合并,所以更好的做法是,借用第二种方法,将整个脚本文件放在一个立即执行的匿名函数之中。
1 | (function (){ |
严格模式对Javascript的语法和行为,都做了一些改变。
在正常模式中,如果一个变量没有声明就赋值,默认是全局变量。严格模式禁止这种用法,全局变量必须显式声明。
1 | ; |
因此,严格模式下,变量都必须先用var命令声明,然后再使用。
Javascript语言的一个特点,就是允许”动态绑定”,即某些属性和方法到底属于哪一个对象,不是在编译时确定的,而是在运行时(runtime)确定的。
严格模式对动态绑定做了一些限制。某些情况下,只允许静态绑定。也就是说,属性和方法到底归属哪个对象,在编译阶段就确定。这样做有利于编译效率的提高,也使得代码更容易阅读,更少出现意外。
具体来说,涉及以下几个方面。
(1)禁止使用with语句
因为with语句无法在编译时就确定,属性到底归属哪个对象。
1 | ; |
(2)创设eval作用域
正常模式下,Javascript语言有两种变量作用域(scope):全局作用域和函数作用域。严格模式创设了第三种作用域:eval作用域。
正常模式下,eval语句的作用域,取决于它处于全局作用域,还是处于函数作用域。严格模式下,eval语句本身就是一个作用域,不再能够生成全局变量了,它所生成的变量只能用于eval内部。
1 |
|
(1)禁止this关键字指向全局对象
1 | function f(){ |
// 返回true,因为严格模式下,this的值为undefined,所以”!this”为true。
因此,使用构造函数时,如果忘了加new,this不再指向全局对象,而是报错。
1 | function f(){ |
(2)禁止在函数内部遍历调用栈
1 | function f1(){ |
严格模式下无法删除变量。只有configurable设置为true的对象属性,才能被删除。
1 | ; |
正常模式下,对一个对象的只读属性进行赋值,不会报错,只会默默地失败。严格模式下,将报错。
1 | ; |
严格模式下,对一个使用getter方法读取的属性进行赋值,会报错。
1 | ; |
严格模式下,对禁止扩展的对象添加新属性,会报错。
1 | ; |
严格模式下,删除一个不可删除的属性,会报错。
1 | ; |
严格模式新增了一些语法错误。
(1)对象不能有重名的属性
正常模式下,如果对象有多个重名属性,最后赋值的那个属性会覆盖前面的值。严格模式下,这属于语法错误。
1 | ; |
(2)函数不能有重名的参数
正常模式下,如果函数有多个重名的参数,可以用arguments[i]读取。严格模式下,这属于语法错误。
1 | ; |
正常模式下,整数的第一位如果是0,表示这是八进制数,比如0100等于十进制的64。严格模式禁止这种表示法,整数第一位为0,将报错。
1 | ; |
arguments是函数的参数对象,严格模式对它的使用做了限制。
(1)不允许对arguments赋值
1 | ; |
(2)arguments不再追踪参数的变化
1 | function f(a) { |
(3)禁止使用arguments.callee
这意味着,你无法在匿名函数内部调用自身了。
1 | ; |
将来Javascript的新版本会引入”块级作用域”。为了与新版本接轨,严格模式只允许在全局作用域或函数作用域的顶层声明函数。也就是说,不允许在非函数的代码块内声明函数。
1 | ; |
为了向将来Javascript的新版本过渡,严格模式新增了一些保留字:implements, interface, let, package, private, protected, public, static, yield。
使用这些词作为变量名将会报错。
1 | function package(protected) { // 语法错误 |
此外,ECMAscript第五版本身还规定了另一些保留字(class, enum, export, extends, import, super),以及各大浏览器自行增加的const保留字,也是不能作为变量名的。
五、参考链接
MDN,Strict mode
Dr. Axel Rauschmayer,JavaScript’s strict mode: a summary
Java 转型问题其实并不复杂,只要记住一句话:父类引用指向子类对象。
什么叫父类引用指向子类对象,且听我慢慢道来.
从2个名词开始说起:向上转型(upcasting) 、向下转型(downcasting).
举个例子:有2个类,Father是父类,Son类继承自Father。
1 | Father f1 = new Son(); // 这就叫 upcasting (向上转型) |
第2个例子:
1 | Father f2 = new Father(); |
你或许会问,第1个例子中:Son s1 = (Son)f1; 为什么是正确的呢?
很简单因为f1指向一个子类对象,Father f1 = new Son(); 子类s1引用当然可以指向子类对象了。
而f2 被传给了一个Father对象,Father f2 = new Father();子类s1引用不能指向父类对象。
总结:
1。父类引用指向子类对象,而子类引用不能指向父类对象。
2。把子类对象直接赋给父类引用叫upcasting向上转型,向上转型不用强制转换。
如:Father f1 = new Son();
3。把指向子类对象的父类引用赋给子类引用叫向下转型(downcasting),要强制转换。
如:f1 就是一个指向子类对象的父类引用。把f1赋给子类引用s1即 Son s1 = (Son)f1;
其中f1前面的(Son)必须加上,进行强制转换。
网站数据统计分析工具是网站站长和运营人员经常使用的一种工具,比较常用的有谷歌分析、百度统计和
腾讯分析等等。所有这些统计分析工具的第一步都是网站访问数据的收集。目前主流的数据收集方式基本都是基于javascript的。本文将简要分析这种数据收集的原理,并一步一步实际搭建一个实际的数据收集系统。
简单来说,网站统计分析工具需要收集到用户浏览目标网站的行为(如打开某网页、点击某按钮、将商品加入购物车等)及行为附加数据(如某下单行为产生的订单金额等)。早期的网站统计往往只收集一种用户行为:页面的打开。而后用户在页面中的行为均无法收集。这种收集策略能满足基本的流量分析、来源分析、内容分析及访客属性等常用分析视角,但是,随着ajax技术的广泛使用及电子商务网站对于电子商务目标的统计分析的需求越来越强烈,这种传统的收集策略已经显得力不能及。
后来,Google在其产品谷歌分析中创新性的引入了可定制的数据收集脚本,用户通过谷歌分析定义好的可扩展接口,只需编写少量的javascript代码就可以实现自定义事件和自定义指标的跟踪和分析。目前百度统计、搜狗分析等产品均照搬了谷歌分析的模式。
其实说起来两种数据收集模式的基本原理和流程是一致的,只是后一种通过javascript收集到了更多的信息。下面看一下现在各种网站统计工具的数据收集基本原理。
首先通过一幅图总体看一下数据收集的基本流程。
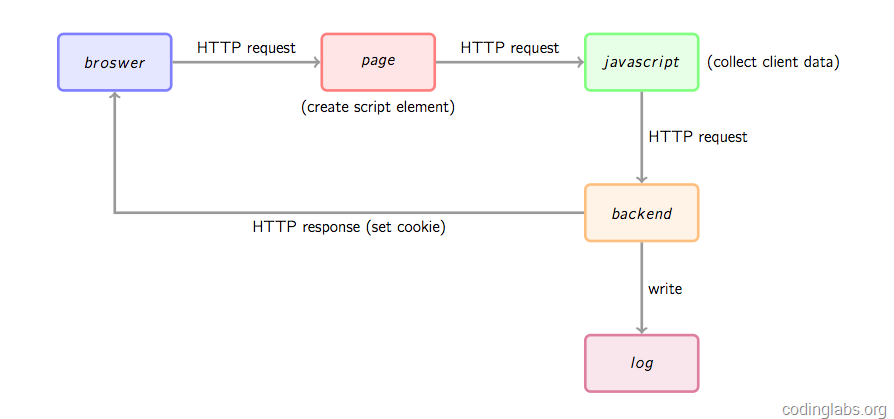
首先,用户的行为会触发浏览器对被统计页面的一个http请求,这里姑且先认为行为就是打开网页。当网页被打开,页面中的埋点javascript片段会被执行,用过相关工具的朋友应该知道,一般网站统计工具都会要求用户在网页中加入一小段javascript代码,这个代码片段一般会动态创建一个script标签,并将src指向一个单独的js文件,此时这个单独的js文件(图1中绿色节点)会被浏览器请求到并执行,这个js往往就是真正的数据收集脚本。数据收集完成后,js会请求一个后端的数据收集脚本(图1中的backend),这个脚本一般是一个伪装成图片的动态脚本程序,可能由php、python或其它服务端语言编写,js会将收集到的数据通过http参数的方式传递给后端脚本,后端脚本解析参数并按固定格式记录到访问日志,同时可能会在http响应中给客户端种植一些用于追踪的cookie。
上面是一个数据收集的大概流程,下面以谷歌分析为例,对每一个阶段进行一个相对详细的分析。
若要使用谷歌分析(以下简称GA),需要在页面中插入一段它提供的javascript片段,这个片段往往被称为埋点代码。下面是我的博客中所放置的谷歌分析埋点代码截图:

其中_gaq是GA的的全局数组,用于放置各种配置,其中每一条配置的格式为:
1 | _gaq.push(['Action', 'param1', 'param2', ...]); |
Action指定配置动作,后面是相关的参数列表。GA给的默认埋点代码会给出两条预置配置,_setAccount用于设置网站标识ID,这个标识ID是在注册GA时分配的。_trackPageview告诉GA跟踪一次页面访问。更多配置请参考:https://developers.google.com/analytics/devguides/collection/gajs/。实际上,这个_gaq是被当做一个FIFO队列来用的,配置代码不必出现在埋点代码之前,具体请参考上述链接的说明。
就本文来说,_gaq的机制不是重点,重点是后面匿名函数的代码,这才是埋点代码真正要做的。这段代码的主要目的就是引入一个外部的js文件(ga.js),方式是通过document.createElement方法创建一个script并根据协议(http或https)将src指向对应的ga.js,最后将这个element插入页面的dom树上。
注意ga.async = true的意思是异步调用外部js文件,即不阻塞浏览器的解析,待外部js下载完成后异步执行。这个属性是HTML5新引入的。
数据收集脚本(ga.js)被请求后会被执行,这个脚本一般要做如下几件事:
通过浏览器内置javascript对象收集信息,如页面title(通过document.title)、referrer(上一跳url,通过document.referrer)、用户显示器分辨率(通过windows.screen)、cookie信息(通过document.cookie)等等一些信息。
解析_gaq收集配置信息。这里面可能会包括用户自定义的事件跟踪、业务数据(如电子商务网站的商品编号等)等。
上面两步收集的数据按预定义格式解析并拼接。
请求一个后端脚本,将信息放在http request参数中携带给后端脚本。
这里唯一的问题是步骤4,javascript请求后端脚本常用的方法是ajax,但是ajax是不能跨域请求的。这里ga.js在被统计网站的域内执行,而后端脚本在另外的域(GA的后端统计脚本是http://www.google-analytics.com/__utm.gif,ajax行不通。一种通用的方法是js脚本创建一个Image对象,将Image对象的src属性指向后端脚本并携带参数,此时即实现了跨域请求后端。这也是后端脚本为什么通常伪装成gif文件的原因。通过http抓包可以看到ga.js对__utm.gif的请求:
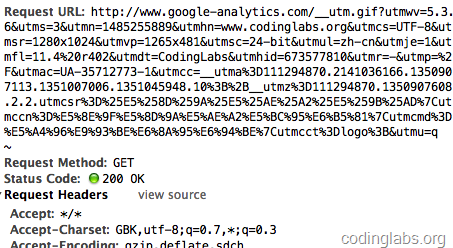
可以看到ga.js在请求__utm.gif时带了很多信息,例如utmsr=1280×1024是屏幕分辨率,utmac=UA-35712773-1是_gaq中解析出的我的GA标识ID等等。
值得注意的是,__utm.gif未必只会在埋点代码执行时被请求,如果用_trackEvent配置了事件跟踪,则在事件发生时也会请求这个脚本。
由于ga.js经过了压缩和混淆,可读性很差,我们就不分析了,具体后面实现阶段我会实现一个功能类似的脚本。
后端脚本执行阶段
GA的__utm.gif是一个伪装成gif的脚本。这种后端脚本一般要完成以下几件事情:
解析http请求参数的到信息。
从服务器(WebServer)中获取一些客户端无法获取的信息,如访客ip等。
将信息按格式写入log。
生成一副1×1的空gif图片作为响应内容并将响应头的Content-type设为image/gif。
在响应头中通过Set-cookie设置一些需要的cookie信息。
之所以要设置cookie是因为如果要跟踪唯一访客,通常做法是如果在请求时发现客户端没有指定的跟踪cookie,则根据规则生成一个全局唯一的cookie并种植给用户,否则Set-cookie中放置获取到的跟踪cookie以保持同一用户cookie不变(见图4)。
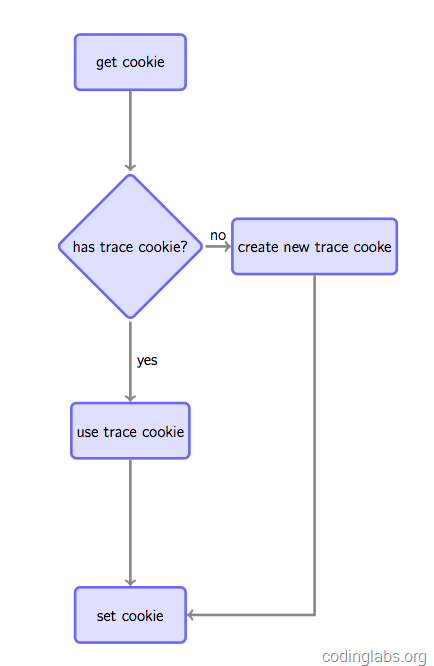
这种做法虽然不是完美的(例如用户清掉cookie或更换浏览器会被认为是两个用户),但是是目前被广泛使用的手段。注意,如果没有跨站跟踪同一用户的需求,可以通过js将cookie种植在被统计站点的域下(GA是这么做的),如果要全网统一定位,则通过后端脚本种植在服务端域下(我们待会的实现会这么做)。
根据上述原理,我自己搭建了一个访问日志收集系统。总体来说,搭建这个系统要做如下的事:
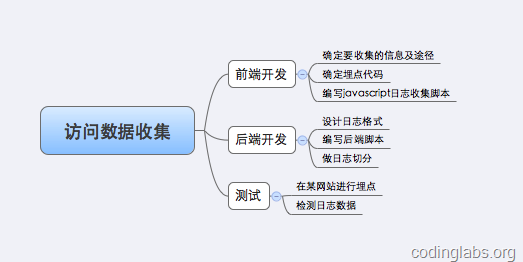
下面详述每一步的实现。我将这个系统叫做MyAnalytics。
为了简单起见,我不打算实现GA的完整数据收集模型,而是收集以下信息。
| 名称 | 途径 | 备注 |
|---|---|---|
| 访问时间 | web server | Nginx $msec |
| IP | web server | Nginx $remote_addr |
| 域名 | javascript | document.domain |
| URL | javascript | document.URL |
| 页面标题 | javascript | document.title |
| 分辨率 | javascript | window.screen.height & width |
| 颜色深度 | javascript | window.screen.colorDepth |
| Referrer | javascript | document.referrer |
| 浏览客户端 | web server | Nginx $http_user_agent |
| 客户端语言 | javascript | navigator.language |
| 访客标识 | cookie | |
| 网站标识 | javascript | 自定义对象 |
埋点代码我将借鉴GA的模式,但是目前不会将配置对象作为一个FIFO队列用。一个埋点代码的模板如下:
1 |
|
这里我启用了二级域名analytics.codinglabs.org,统计脚本的名称为ma.js。当然这里有一点小问题,因为我并没有https的服务器,所以如果一个https站点部署了代码会有问题,不过这里我们先忽略吧。
我写了一个不是很完善但能完成基本工作的统计脚本ma.js:
1 | (function() { |
整个脚本放在匿名函数里,确保不会污染全局环境。功能在原理一节已经说明,不再赘述。其中1.gif是后端脚本。
日志采用每行一条记录的方式,采用不可见字符^A(ascii码0×01,Linux下可通过ctrl + v ctrl + a输入,下文均用“^A”表示不可见字符0×01),具体格式如下:
时间^AIP^A域名^AURL^A页面标题^AReferrer^A分辨率高^A分辨率宽^A颜色深度^A语言^A客户端信息^A用户标识^A网站标识
为了简单和效率考虑,我打算直接使用nginx的access_log做日志收集,不过有个问题就是nginx配置本身的逻辑表达能力有限,所以我选用了OpenResty做这个事情。OpenResty是一个基于Nginx扩展出的高性能应用开发平台,内部集成了诸多有用的模块,其中的核心是通过ngx_lua模块集成了Lua,从而在nginx配置文件中可以通过Lua来表述业务。关于这个平台我这里不做过多介绍,感兴趣的同学可以参考其官方网站http://openresty.org/,或者这里有其作者章亦春(agentzh)做的一个非常有爱的介绍OpenResty的slide:http://agentzh.org/misc/slides/ngx-openresty-ecosystem/,关于ngx_lua可以参考:https://github.com/chaoslawful/lua-nginx-module。
首先,需要在nginx的配置文件中定义日志格式:
log_format tick "$msec^A$remote_addr^A$u_domain^A$u_url^A$u_title^A$u_referrer^A$u_sh^A$u_sw^A$u_cd^A$u_lang^A$http_user_agent^A$u_utrace^A$u_account";注意这里以u_开头的是我们待会会自己定义的变量,其它的是nginx内置变量。
然后是核心的两个location:
1 | location /1.gif { |
要完全解释这段脚本的每一个细节有点超出本文的范围,而且用到了诸多第三方ngxin模块(全都包含在OpenResty中了),重点的地方我都用注释标出来了,可以不用完全理解每一行的意义,只要大约知道这个配置完成了我们在原理一节提到的后端逻辑就可以了。
真正的日志收集系统访问日志会非常多,时间一长文件变得很大,而且日志放在一个文件不便于管理。所以通常要按时间段将日志切分,例如每天或每小时切分一个日志。我这里为了效果明显,每一小时切分一个日志。我是通过crontab定时调用一个shell脚本实现的,shell脚本如下:
1 | _prefix="/path/to/nginx" |
这个脚本将ma.log移动到指定文件夹并重命名为ma-{yyyymmddhh}.log,然后向nginx发送USR1信号令其重新打开日志文件。
然后再/etc/crontab里加入一行:
59 * * * * root /path/to/directory/rotatelog.sh在每个小时的59分启动这个脚本进行日志轮转操作。
下面可以测试这个系统是否能正常运行了。我昨天就在我的博客中埋了相关的点,通过http抓包可以看到ma.js和1.gif已经被正确请求:
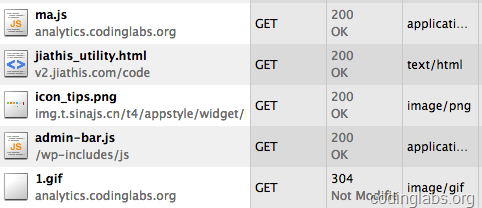
同时可以看一下1.gif的请求参数:

相关信息确实也放在了请求参数中。
然后我tail打开日志文件,然后刷新一下页面,因为没有设access log buffer, 我立即得到了一条新日志:
1 | 1351060731.360^A0.0.0.0^Awww.codinglabs.org^Ahttp://www.codinglabs.org/ |
注意实际上原日志中的^A是不可见的,这里我用可见的^A替换为方便阅读,另外IP由于涉及隐私我替换为了0.0.0.0。
看一眼日志轮转目录,由于我之前已经埋了点,所以已经生成了很多轮转文件:

通过上面的分析和开发可以大致理解一个网站统计的日志收集系统是如何工作的。有了这些日志,就可以进行后续的分析了。本文只注重日志收集,所以不会写太多关于分析的东西。
注意,原始日志最好尽量多的保留信息而不要做过多过滤和处理。例如上面的MyAnalytics保留了毫秒级时间戳而不是格式化后的时间,时间的格式化是后面的系统做的事而不是日志收集系统的责任。后面的系统根据原始日志可以分析出很多东西,例如通过IP库可以定位访问者的地域、user agent中可以得到访问者的操作系统、浏览器等信息,再结合复杂的分析模型,就可以做流量、来源、访客、地域、路径等分析了。当然,一般不会直接对原始日志分析,而是会将其清洗格式化后转存到其它地方,如MySQL或HBase中再做分析。
分析部分的工作有很多开源的基础设施可以使用,例如实时分析可以使用Storm,而离线分析可以使用Hadoop。当然,在日志比较小的情况下,也可以通过shell命令做一些简单的分析,例如,下面三条命令可以分别得出我的博客在今天上午8点到9点的访问量(PV),访客数(UV)和独立IP数(IP):
1 | awk -F^A '{print $1}' ma-2012102409.log | wc -l |
其它好玩的东西朋友们可以慢慢挖掘。
GA的开发者文档:https://developers.google.com/analytics/devguides/collection/gajs/
关于Nginx可以参考:http://wiki.nginx.org/Main
OpenResty的官方网站为:http://openresty.org
ngx_lua模块可参考:https://github.com/chaoslawful/lua-nginx-module
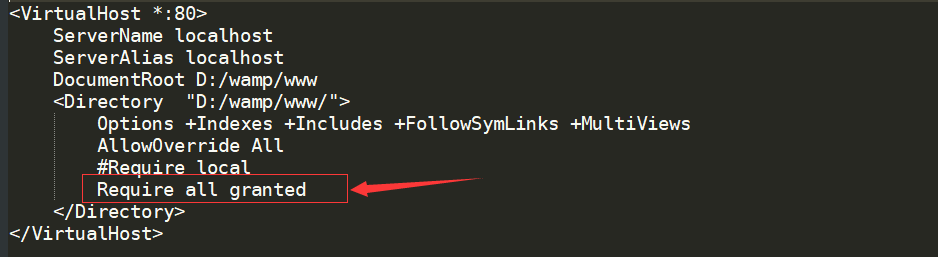
配置正向代理很简单,此处我们配置vhost来实现代理, 只需要在浏览器的Proxy选项里加入你的Apache配置的vHost主机即可
http.conf开启代理模块
1 | LoadModule proxy_module modules/mod_proxy.so |
引入vhost文件
1 | Include conf/extra/httpd-vhosts.conf |
如果你想监听别的端口, 修改Listen参数
1 | Listen 80 |
将想监听的端口全都写上,相应的, 在vhost文件里写上
1 | NameVirtualHost *:80 |
NameVirtualHost表示vhost匹配的请求的ip和端口那些会取扫描vhost
1 | <VirtualHost *:80> |
先看
1 | <VirtualHost *:80> |
VirtualHost 后面的参数表示的是该VHost的IP/域名/和端口, 你可以写 :
(1) IP: port, 例如 <VirtualHost 175.2.22.65:8088>, 访问的时候通过IP访问
(2) Domain, 例如 <VirtualHost www.test1.com>, 访问的时候通过域名访问, 也可以指定里面的ServerName来指定域名
(3) *, 表示匹配所有对Apache监听主机的请求, 只要是apache监听到的请求都可以匹配该虚拟主机
此处表示的就是监听所有80端口的请求, 但是由于ServerName里写了www.test.com, 所以这个vhost匹配的是www.test.com:80,
现在看正向代理设置那一段
ProxyRequests On:开启Apache正向代理
ProxyVia On:控制位于代理服务器链中的代理请求的流向
引用Apache2.2官方文档中对ProxyVia的解释如下:
如果设置为默认值Off ,将不会采取特殊的处理。如果一个请求或应答包含”Via:”头,将不进行任何修改而直接通过。如果设置为On每个请求和应答都会对应当前主机得到一个”Via:”头。如果设置为Full ,每个产生的”Via:”头中都会额外加入Apache服务器的版本,以”Via:”注释域出现。如果设置为Block ,每个代理请求中的所有”Via:”头行都将被删除。且不会产生新的”Via:”头。<Proxy *>…</Proxy>:用来控制谁可以访问你的代理
1 | <Proxy *> |
2.1 Apache设置
1 | <VirtualHost *:80> |
现在看反向代理设置那一段
ProxyPass /proxy http://www.proxypass.com/proxy: 将 www.test.com/proxy 域下的所有请求转发给 www.proxypass.com/proxy 代理,例如 www.test.com/proxy/login.php 会交给 www.proxypass.com/proxy/代理
ProxyPassReverse /proxy http://www.proxypass.com/proxy :
www.proxypass.com/proxy/login.php 中有如下代码:
1 |
|
那么在重定向的时候,Apache会将HTTP请求重新设为 http://www.test.com/proxy/result.php, 这样的作用稍后讲解
www.proxypass.com/proxy/result.php 中有如下代码:
1 |
|
2.2 浏览器访问效果
访问 www.test.com/proxy/login.php
Apache将请求交给 www.proxypass.com/proxy/login.php 代理,HTTP请求如图:
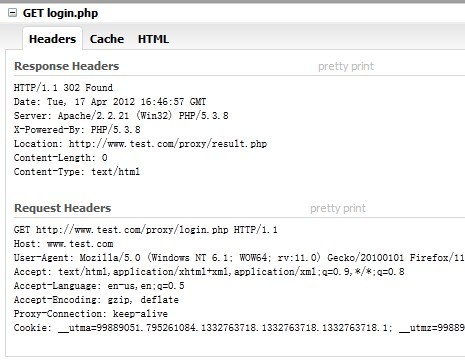
可以发现其实Request中的请求还是 www.test.com 的,但是它确实是由 www.proxypass.com 来处理的
proxypass.com/proxy/login.php 重定向到 proxypass.com/proxy/result.php
页面显示
in proxypass.com
HTTP请求如图:
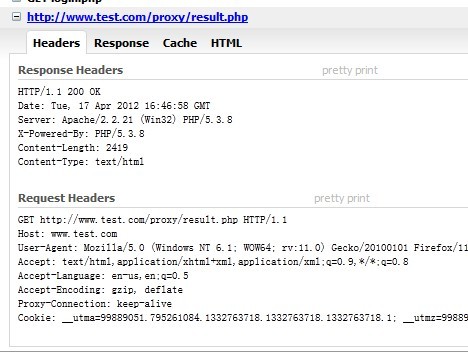
也可以看到请求依然是 www.test.com/proxy/result.php
这里就是 ProxyPassReverse 发挥作用的地方,如果不加这个项,重定向后HTTP请求会如下图:
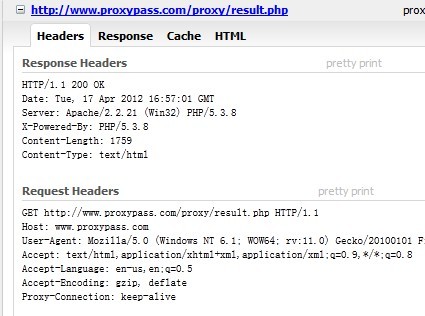
可以发现请求中的GET是 www.proxypass.com 而不是 www.test.com ,这是因为配置了ProxyPassReverse后,proxypass.com/proxy/login.php 在重定向到 proxypass.com/proxy/result.php 时,Apache会将它调整回 test.com/proxy/result.php , 然后Apache再将 test.com/proxy/result.php 代理给 proxypass.com/proxy/result.php,所以说配置了 ProxyPassReverse 后,即使 proxypass.com/proxy 下的程序有重定向到其他 proxypss.com/proxy 的文件的(如 login.php 重定向到 result.php),你也不会在请求中发现 proxypass.com 的影子